Generative Models for Computer Vision
CVPR 2024 Workshop
8:45am - 5:00pm, Tuesday, June 18th, 2024 Summit 432
Overview
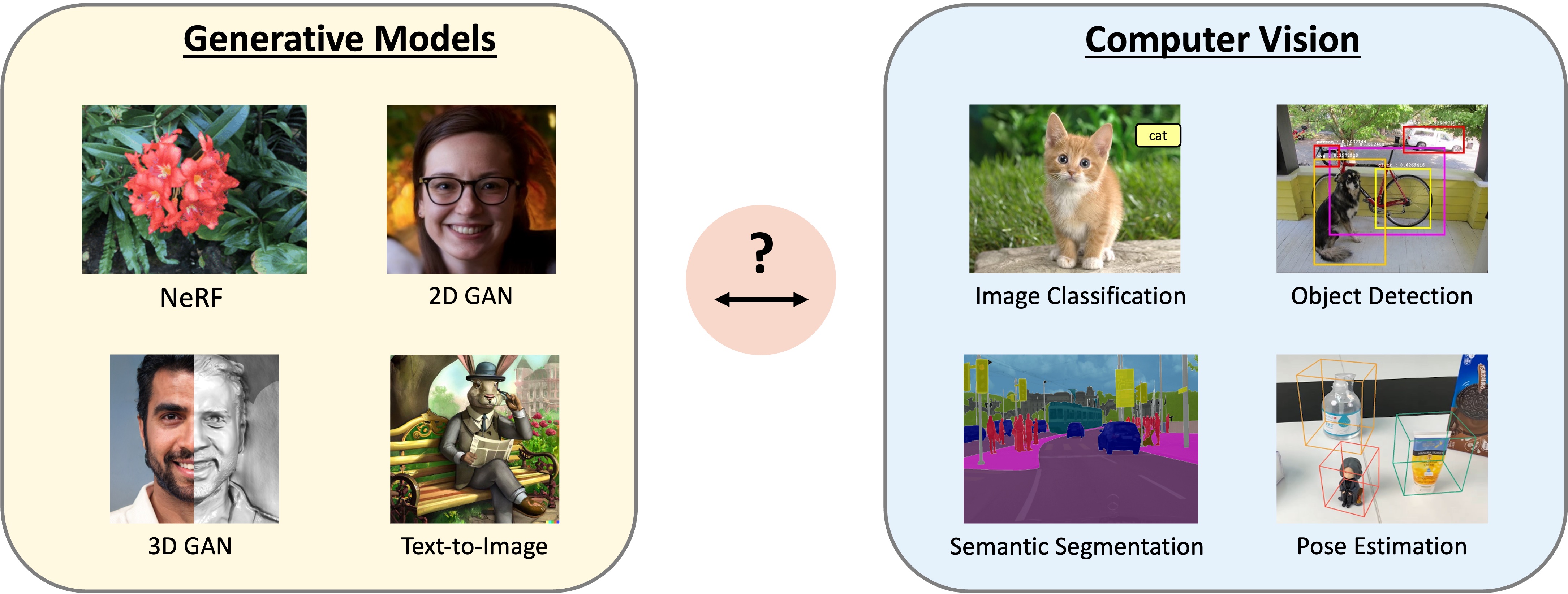
Recent advances in generative modeling leveraging generative adversarial networks, auto-regressive models, neural fields and diffusion models have enabled the synthesis of near photorealistic images, drastically increasing the visibility and popularity of generative modeling across the computer vision research community. However, these impressive advances in generative modeling have not yet found wide adoption in computer vision for visual recognition tasks. In this workshop, we aim to bring together researchers from the fields of image synthesis and computer vision to facilitate discussions and progress at the intersection of those two subfields. We investigate the question: "How can visual recognition benefit from the advances in generative image modeling?". We invite a diverse set of experts to discuss their recent research results and future directions for generative modeling and computer vision, with a particular focus on the intersection between image synthesis and visual recognition. We hope this workshop will lay the foundation for future development of generative models for computer vision tasks.
Invited Speakers








Call for Papers
-
Submission site: https://cmt3.research.microsoft.com/GCV2024
- Advances in generative image models
- Inversion of generative image models
- Training computer vision with realistic synthetic images
- Benchmarking computer vision with generative models
- Analysis-by-synthesis / render-and-compare approaches for visual recognition
- Self-supervised learning with generative models
- Adversarial attacks and defenses with generative models
- Out-of-distribution generalization and detection with generative models
- Ethical considerations in generative modeling, dataset and model biases
Author kit: CVPR Author KIT.
We invite submissions of both short and long papers (4 pages and 8 pages respectively excluding references). The long papers will be included in the proceedings of CVPR. Potential topics include but are not limited to:
Important Dates
| Event | Date (Anywhere on Earth) |
|---|---|
| Workshop paper submission deadline | March 27, 2024 |
| Decisions | April 8, 2024 |
| Camera ready | April 12, 2024 |
Schedule
| 18th of June, UTC-7 | ||
|---|---|---|
| 8:45 | Opening | |
| 9:00 | Invited Talk: Gianluca Corrado | |
| 9:40 | Invited Talk: Siyu Tang | |
| 10:20 | Coffee Break | |
| 10:40 | Invited Talk: Saining Xie | |
| 11:20 | Invited Talk: Alan Yuille | |
| 12:00 | Lunch | |
| 12:30 | Posters (Arch Building, Exhibition Hall, #1-40) | |
| 14:00 | Invited Talk: Jiajun Wu | |
| 14:40 | Invited Talk: Katerina Fragkiadaki | |
| 15:20 | Coffee Break | |
| 15:40 | Invited Talk: Andrea Vedaldi | |
| 16:20 | Invited Talk: Federico Tombari | |
| 17:00 | Closing |
Accepted Papers
Long Papers: To appear in the proceeding of CVPR 2024.
Short Papers:
-
As-Plausible-As-Possible: Plausibility-Aware Mesh Deformation Using 2D Diffusion Priors [Paper] [Supplementary]
Seungwoo Yoo, Kunho Kim, Vladimir Kim, Minhyuk Sung -
Generative AI in Vision: A Survey on Models, Metrics and Applications [Paper]
Gaurav Raut, Apoorv Singh -
Robustness of Generative Models using Language Guidance for Low-Level Vision Tasks: Findings from Depth Estimation [Paper]
Agneet Chatterjee, Tejas Gokhale, Chitta R Baral, Yezhou Yang, Anand Bhattad -
Intrinsic LoRA: A Generalist Approach for Discovering Knowledge in Generative Models [Paper]
Xiaodan Du, Nicholas I Kolkin, Greg Shakhnarovich, Anand Bhattad -
GL-NeRF: Gauss-Laguerre Quadrature for Volume Rendering [Paper]
Yue Fan, Yongqin Xian, Xiaohua Zhai, Alexander Kolesnikov, Muhammad Ferjad Naeem, Bernt Schiele, Federico Tombari -
Synthesizing Image with High-Quality Segmentation Mask by Prompting Large Vision Model [Paper] [Supplementary]
Xuan-Tuyen Tran -
Robust Disaster Assessment from Aerial Imagery Using Text-to-Image Synthetic Data [Paper]
Tarun Kalluri, Jihyeon Lee, Kihyuk Sohn, Sahil Singla, Manmohan Chandraker, Joseph Xu, Jeremiah Liu -
Posterior Distillation Sampling [Paper] [Supplementary]
Juil Koo, Chanho Park, Minhyuk Sung -
Learning Compositional Language-based Object Detection with Diffusion-based Synthetic Data [Paper]
Kwanyong Park, Kuniaki Saito, Donghyun Kim -
KOALA: Fast and Memory-Efficient Latent Diffusion Models via Self-Attention Distillation [Paper]
Youngwan Lee, Kwanyong Park, Yoorhim Cho, Yong-Ju Lee, Sung Ju Hwang -
Turns Out I'm Not Real: Towards Robust Detection of AI-Generated Videos [Paper]
Qingyuan Liu, Pengyuan Shi, Yun-Yun Tsai, Chengzhi Mao, Junfeng Yang -
Diffusion Models for Open-Vocabulary Segmentation [Paper]
Laurynas Karazija, Iro Laina, Andrea Vedaldi, Christian Rupprecht -
Robust Concept Erasure Using Task Vectors [Paper]
Minh Pham, Kelly O. Marshall, Chinmay Hegde, Niv Cohen -
ExtraNeRF: Visibility-Aware View Extrapolation of Neural Radiance Fields with Diffusion Models [Paper]
Meng-Li Shih, Wei-Chiu Ma, Lorenzo Boyice, Aleksander Holynski, Forrester Cole, Brian Curless, Janne Kontkanen -
Do Counterfactual Examples Complicate Adversarial Training? [Paper]
Eric C Yeats, Cameron M Darwin, Eduardo Ortega, Frank Liu, Hai Li -
CAT: Contrastive Adapter Training for Personalized Image Generation [Paper]
Jae Wan Park, Junyoung Koh, Sang Hyun Park, Junha Lee, Min Song -
ZoomLDM: Latent Diffusion Model for multi-scale conditional histopathology image generation [Paper] [Supplementary]
Srikar Yellapragada, Alexandros Graikos, Prateek Prasanna, Rajarsi Gupta, Joel Saltz, Dimitris Samaras -
Causal Diffusion Autoencoders: Toward Representation-Enabled Counterfactual Generation via Diffusion Probabilistic Models [Paper]
Aneesh Komanduri, Chen Zhao, Feng Chen, Xintao Wu -
Spatially Composable Diffusion [Paper]
Ryan Lian, Xingjian Bai, Joy Hsu, Weiyu Liu, Jiayuan Mao, Jiajun Wu -
Learning Multimodal Latent Space with EBM Prior and MCMC Inference [Paper]
Shiyu Yuan, Carlo Lipizzi, Tian Han
Organizers






Top